1.Introduction
本实验将实现一个容错的 键/值 存储系统。在这个实验中将实现Raft,一个复制状态机协议。在下一个实验,你将在Raft的基础上构建一个 键/值 服务。然后,你将在多个复制的状态机上“分片”你的服务以获得更高的性能。
通过将一台服务器的状态复制到多个副本服务器上可以达到容错的目的。这样做使得即使某些服务器出现故障也不会影响整体的服务,而挑战在于故障可能导致副本保存的内容不同。
Raft将客户机的请求组织成一个序列,并称之为’log’,并且保证所有的服务器都能看到同样的log。每一个服务器以log上记录的顺序执行客户请求,并将它们应用到本地的服务器状态上。由于所有的服务器执行相同的操作,所以所有的服务器会有相同的状态。如果一个服务器出现故障但稍后恢复,Raft会负责更新其’log’。只要服务器中的大多数仍然在工作,Raft就会继续操作; 但是如果服务器中的大多数都出现故障而无法正常工作,Raft就不会有进一步的执行。
在本实验中,把Raft看做一个Go对象,并实现它的一些方法。多个Raft实例通过RPC实现相互通信,共同维护’log’。你的Raft将支持无限长的命令序列,即’log entries’,这些entries用索引进行编号,且最终会被提交到’log’。
主要的思路可以参照In Search of an Understandable Consensus Algorithm(Extended Version)中的Figure 2。实现的内容主要是保存服务器的状态信息,并在服务器故障时根据状态信息重启服务器。
2.The code
通过修改raft/raft.go来完成实验。以下是一些接口的介绍:
// create a new Raft server instance:
rf := Make(peers, me, persister, applyCh)
// start agreement on a new log entry:
rf.Start(command interface{}) (index, term, isleader)
// ask a Raft for its current term, and whether it thinks it is leader
rf.GetState() (term, isLeader)
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester).
type ApplyMsg
调用 Make(peers, me,…) 来创建一个Raft实例。
Start(command) 使 Raft 实例将 command 加入到 log,且 Start(…) 不需要等到 log 添加完成后再返回。
对于每一个新提交的 log entry,每一个副本服务器都应该发送一个 ApplyMsg 给 Make(…) 中的 applyCh。
raft.go 中包含了发送 RPC(sendRequestVote()) 和处理 RPC(RequestVote()) 的示例。本实验应该使用Go的 (src/labrpc) 实现RPC。
3.Part 2A: leader election
3.1 Task
实现 Raft 的 leader election 以及 heartbeats(AppendEntries RPCs with no log entries)。
Part 2A的目标是:
对于被选出的 leader, 如果没有失效,它仍然是 leader;如果 old leader 失效,就重新选取一个 new leader。
3.2 Hint
-
参考 Figure 2 中接收和发送RPC,选举,以及与选举有关的状态的部分。
-
将选举状态加入
Raft struct,还需要定义一个结构体保存log entry的信息。 -
填写
RequestVoteArgs struct和RequestVoteReply struct。 -
改写
Make(), 创建一个后台 goroutine, 从而在本服务器没有从别的服务器接收到信息时,可以通过发送 RequestVote RPCs 周期性的唤醒新一轮 leader election, 这样就可以使服务器知道谁是 leader。 -
实现
RequestVote()RPC handler,这样服务器就可以进行投票。 -
为了实现 heartbeats,定义一个
AppendEntries RPC struct, 并且 leader 会周期性的发送它,且不超过10次/秒。 -
写一个
AppendEntries RPC handler方法重置 election timeout, 这样当一个服务器被选为 leader 时, 其他服务器就不会被选为 leader。 -
确保不同服务器的 election timeouts 不会在同一时间触发。换种说法就是:所有服务器都只为自己投票,但是没有谁会成为 leader。
-
在 old leader 失效5秒之内,new leader 就应该被选出。leader election 也许会有很多轮,因为可能出现 split vote。必须选择足够短的 election timeout(以及 heartbeat),这样即使选举需要多轮,也很可能在不到五秒的时间内完成。论文中Section 5.2 提到了election timeouts 一般设置为150-300毫秒,但是本实验中应该比这个范围大一些,具体设置为多少?
-
实现周期性:最简单的方式是创建一个 goroutine,在循环中调用
time.Sleep()。(参见Make()为此目的创建的ticker() goroutine) -
实现
GetState() -
tester 在永久关闭实例时调用 Raft 的 rf.Kill() 。 你可以使用 rf.killed() 检查是否已调用 Kill()。 你可能希望在所有循环中都这样做,以避免 dead Raft 实例打印令人困惑的信息。
-
Go RPC 只发送名称以大写字母开头的结构体字段。子结构还必须具有大写的字段名称(例如数组中的 log 记录字段)。labgob 包会警告你这一点;不要忽略警告。
4.Solution
4.1 Work flow
在做了大量的前期工作比如读论文,看go教程,看课程视频之后,说实话,对raft的认识就一个字:“懵逼”,只知道2A部分要做的内容是leader election,还有就是主要参照论文里面的Figure 2。
在找到一个raft可视化的示例:raft之后,再结合Figure 2,总算大概对leader election有了个基本的认识,大概流程如下:
一些基本概念
-
1.所有的服务器之后我都会称之为结点(为了简化问题),并且这些结点只有三种状态:跟随者,候选者,领导者。
-
2.在leader election期间,会设置两个计时器,分别是election timer(or election timeout) 和 heartbeat timer(or heartbeat timeout)。
-
3.领导者是有任期的,用 term 表示。
进入正题, 开始 leader election
-
1.“等待戈多”:首先所有的结点都被初始化为跟随者。这些货干什么呢?说白了就是:在一个时间段内等待候选者或者领导者给他下命令干一些事,如果在这个时间段内没人管他,那么好了,他就摇身一变,成为候选者。其中,时间段就是‘election timer’。
-
2.“参加竞选”:跟随者在成为候选者之后,会迅速开启一轮选举,具体做以下几件事:
增加自己的任期:currentTerm + 1
给自己投票
重新设置自己的 election timer
向其他结点发出请求,请他们给自己投票
-
3.“投票了!”:如果接收到请求的结点还没有投过票,那么它就给向它请求的候选者投出宝贵的一票;还有就是重新设置自己的election timer。
-
4.“高票当选”:一旦候选者获得超过一半的投票数,那么他就成为新一任领导者。在成为领导者之后,它会周期性(heartbeat timer)地跟他的跟随者们联系,告诉他们:我还是你们的领导,都给我好好听话,干好自己的活。他的跟随者们也会给出回应:好的,老板。这些跟随者们还会重置自己的election timer。(道理你懂的!万一election timeout,跟随者就会变成候选者,这不是给领导添堵吗?当领导的当然要尽量避免这一点)
-
5.“任期也有尽头”:领导的任期是有尽头的!尽管领导者会周期性的重置跟随者的election timer,但架不住会发生意外啊,总有一些跟随者election timer会超时,成为候选者,这就标志着本届领导者的任期到头了,候选者会开启下一届的选举。
-
6.“分开选举”:有时会出现多个候选者同时竞选,这就是分开选举,不过最后只能有一个领导者。
整个流程很像现实生活中的选举,并不是很难理解。
4.2 Code
至此,已经大概知道了Raft的工作流程和go的基本语法,可是开始Coding才发现,事情似乎没有想的那么简单。
刚开始的思路很简单,就是按照Raft工作流程,再参照Figure 2,可是全部完成后,无论如何都通不过测试,真是蛋疼,这玩意儿真是bug都不好找,没有办法,于是看了课程视频中讲解Raft实验代码的部分,看完以后,明确了一些编程原则和模式。
再来一遍:
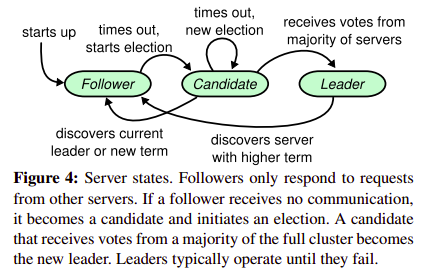
这一次,我发现,其实,要想理清逻辑,论文中的Figure 4也同样重要!
1.Raft struct
根据Figure 2的提示,选举期间需要的字段有
currentTerm
votedFor
但是仅仅这两个是不够的,还需要再额外加两个字段
state // 表明当前结点的状态{Follower, Candidate, Leader}
heartBeat // 记录当前结点是否收到过Leader发来的heartbeas
于是在Raft struct中添加了如下状态:
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
state int
heartBeat int64
currentTerm int
votedFor int
在接下来的Coding中,始终记得两件事:
- 结点最重要的两个字段是state和currentTerm,时刻注意它们是否需要修改
- Figure 2 和 Figure 4 是重要的依据,Coding就是实现Figure 4的状态转换,而Figure 2则指明了结点处于不同状态时要做的事情。
2. Initialize Raft
根据Figure 4,结点刚开始的状态是Follower,再根据Figure 2的提示,于是初始化结点:
// Your initialization code here (2A, 2B, 2C).
rf.state = Follower
rf.heartBeat = time.Now().UnixNano() / 1e6
rf.currentTerm = 0
rf.votedFor = -1
3.Election timeout
根据Figure 4,Follower会在election timeout之后转换为Candidate,这件事在ticker()中完成:
func (rf *Raft) ticker() {
for rf.killed() == false {
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// time.Sleep().
rf.mu.Lock()
before := rf.heartBeat
rf.mu.Unlock()
// 根据Hint,election timeout设置为[150, 450]
rand.Seed(time.Now().UnixNano())
d := rand.Intn(300) + 150
time.Sleep(time.Duration(d) * time.Millisecond)
rf.mu.Lock()
after := rf.heartBeat
state := rf.state
rf.mu.Unlock()
// Figure 4显示的很清楚:如果Follower或Candidate在election timeout时没有收到heartbeat,就会开启选举
if after == before && state != Leader {
go rf.startElection()
}
}
}
4.Election
结点成为Candidate后会发起选举。startElection()的基本逻辑很简单:向其他结点发出投票请求RPCs,再根据回应进行状态转换。根据Figure 4,Candidate此时有两种转换可能,一种是得到大多数支持而转换为Leader,另一种是更新currentTerm转换为Follower。
startElection():
func (rf *Raft) startElection() {
rf.mu.Lock()
rf.state = Candidate
rf.currentTerm++
rf.votedFor = rf.me
vote := 1
term := rf.currentTerm
rf.mu.Unlock()
var wg sync.WaitGroup
for server, _ := range rf.peers {
if server == rf.me {
continue
}
wg.Add(1)
go func(server int) {
voteGranted, replyTerm := rf.callSendRequestVote(server, term)
wg.Done()
rf.mu.Lock()
defer rf.mu.Unlock()
if !voteGranted {
if replyTerm != -1 {
rf.currentTerm = replyTerm
rf.state = Follower
}
return
}
if rf.state != Candidate || rf.currentTerm > term {
return
}
vote++
if vote > len(rf.peers) / 2 {
rf.state = Leader
}
}(server)
}
wg.Wait()
}
RPCs的实现: 参数:
// 由Figure 2易知
type RequestVoteReply struct {
// Your data here (2A).
Term int
VoteGranted bool
}
type AppendEntriesArgs struct {
Term int
}
RequestVote():
//
// example RequestVote RPC handler.
//
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
// 由Figure 2提示可知
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
}
if args.Term > rf.currentTerm {
rf.state = Follower
rf.currentTerm = args.Term
rf.votedFor = args.CandidateId
reply.VoteGranted = true
return
}
if args.Term == rf.currentTerm {
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
rf.votedFor = args.CandidateId
reply.VoteGranted = true
}
return
}
}
课程视频中关于Raft实验代码的部分,第二个助教提到,调用RPCs时尽量不要使用加锁和解锁,于是增加了callSendRequestVote(),只为了传递term这个参数
func (rf *Raft) callSendRequestVote(server int, term int) (bool, int) {
args := RequestVoteArgs{
Term : term,
CandidateId : rf.me,
}
reply := RequestVoteReply{
Term : -1,
VoteGranted : false,
}
ok := rf.sendRequestVote(server, &args, &reply)
if !ok {
return false, -1
}
return reply.VoteGranted, reply.Term
}
5.Heartbeat
选举完成后,Leader会定期发出heartbeat,根据Figure 4,Leader的状态转换只有一种可能,就是因为更新currentTerm转换为Follower,具体的实现主要有:周期性向其他结点发出heartbeat RPCs,并根据回应进行状态转换。
// start ticker goroutine to start elections
go rf.ticker()
// heartbeat
go rf.heartBeatTicker()
heartBeatTicker():
func (rf *Raft) heartBeatTicker() {
for rf.killed() == false {
time.Sleep(time.Duration(150) * time.Millisecond)
rf.mu.Lock()
state := rf.state
rf.mu.Unlock()
if state == Leader {
go rf.leaderWork()
}
}
}
leaderWork():
func (rf *Raft) leaderWork() {
rf.mu.Lock()
term := rf.currentTerm
rf.mu.Unlock()
for server, _ := range rf.peers {
if server == rf.me {
continue
}
go func(server int) {
_, replyTerm := rf.callSendAppendEntries(server, term)
if replyTerm != -1 {
rf.mu.Lock()
rf.currentTerm = replyTerm
rf.state = Follower
rf.mu.Unlock()
}
}(server)
}
}
RPC实现仿照之前的即可:
参数:
type AppendEntriesArgs struct {
Term int
}
type AppendEntriesReply struct {
Term int
}
AppendEntries():
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term < rf.currentTerm {
reply.Term = args.Term
} else {
rf.currentTerm = args.Term
rf.state = Follower
rf.heartBeat = time.Now().UnixNano() / 1e6
}
}
sendAppendEntries():
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
}
callSendRequestVote():
func (rf *Raft) callSendRequestVote(server int, term int) (bool, int) {
args := RequestVoteArgs{
Term : term,
CandidateId : rf.me,
}
reply := RequestVoteReply{
Term : -1,
VoteGranted : false,
}
ok := rf.sendRequestVote(server, &args, &reply)
if !ok {
return false, -1
}
return reply.VoteGranted, reply.Term
}
6.GetState()
最后,不要忘了GetState():
// return currentTerm and whether this server
// believes it is the leader.
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (2A).
rf.mu.Lock()
defer rf.mu.Unlock()
term = rf.currentTerm
isleader = rf.state == Leader
return term, isleader
}
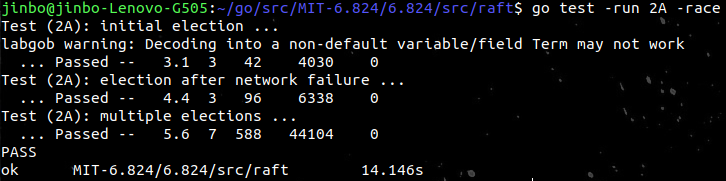
7.Result