
Architecture
A GFS cluster consists of a single master and multiple chunkservers and is accessed by multiple clients, as shown in Figure 1.
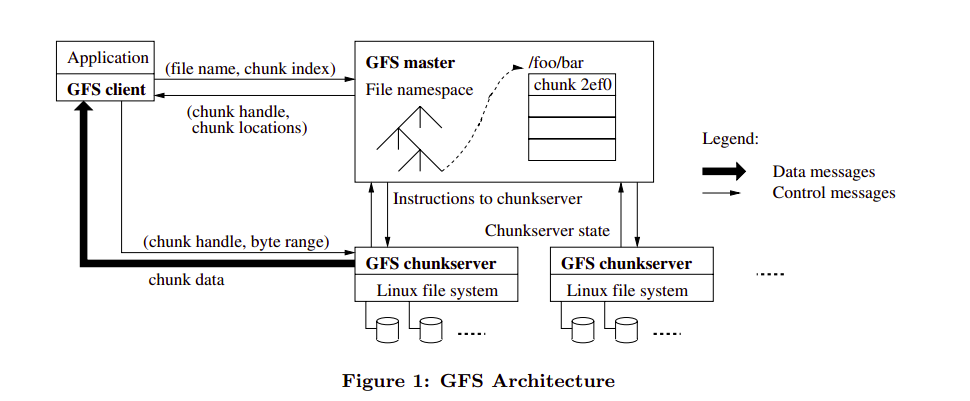
1. Single Master
Having a single master enables the master to make sophisticated chunk placement and replication decisions using global knowledge.
2. Chunk Size
Chunk size is one of the key design parameters. It has been chosen 64 MB, which is much larger than typical file system block sizes. Each chunk replica is stored as a plain Linux file on a chunkserver and is extended only as needed.
3. Metadata
The master stores three major types of metadata:
- the file and chunk namespaces
- the mapping from files to chunks
- the locations of each chunk’s replicas
All metadata is kept in the master’s memory.
The first two types (namespaces and file-to-chunk mapping) are also kept persistent by logging mutations to an operation log stored on the master’s local disk and replicated on remote machines.
But the master does not store chunk location information persistently.
3.1 In-Memory Data Structures
The master maintains less than 64 bytes of metadata for each 64 MB chunk.
3.2 Chunk Locations
The master does not keep a persistent record of which chunkservers have a replica of a given chunk.It simply polls chunkservers for that information at startup. The master can keep itself up-to-date thereafter because it controls all chunk placement and monitors chunkserver status with regular HeartBeat messages.
3.3 Operation Log
The operation log contains a historical record of critical metadata changes.
We replicate it on multiple remote machines and respond to a client operation only after flushing the corresponding log record to disk both locally and remotely.
The master recovers its file system state by replaying the operation log.To minimize startup time, we must keep the log small. The master checkpoints its state whenever the log grows beyond a certain size so that it can recover by loading the latest checkpoint from local disk and replaying only the limited number of log records after that.The checkpoint is in a compact B-tree like form that can be directly mapped into memory and used for namespace lookup without extra parsing.
4. Consistency Model
GFS has a relaxed consistency model that supports highly distributed applications well but remains relatively simple and efficient to implement.
System Interactions
We now describe how the client, master, and chunkservers interact to implement data mutations, atomic record append, and snapshot.
1. Leases and Mutation Order
A mutation is an operation that changes the contents or metadata of a chunk such as a write or an append operation. Each mutation is performed at all the chunk’s replicas.We use leases to maintain a consistent mutation order across replicas.The master grants a chunk lease to one of the replicas, which we call the primary.The primary picks a serial order for all mutations to the chunk.All replicas follow this order when applying mutations.Thus, the global mutation order is defined first by the lease grant order chosen by the master, and within a lease by the serial numbers assigned by the primary.
In Figure 2, we illustrate this process by following the control flow of a write through these numbered steps.
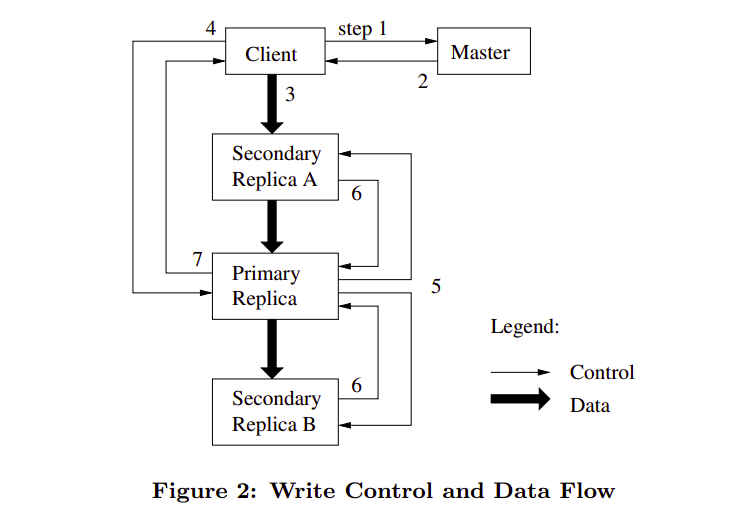
- 1.The client asks the master which chunkserver holds the current lease for the chunk and the locations of the other replicas. If no one has a lease, the master grants one to a replica it chooses (not shown).
- 2.The master replies with the identity of the primary and the locations of the other (secondary) replicas. The client caches this data for future mutations. It needs to contact the master again only when the primary becomes unreachable or replies that it no longer holds a lease.
- 3.The client pushes the data to all the replicas. A client can do so in any order. Each chunkserver will store the data in an internal LRU buffer cache until the data is used or aged out.
- 4.Once all the replicas have acknowledged receiving the data, the client sends a write request to the primary. The request identifies the data pushed earlier to all of the replicas. The primary assigns consecutive serial numbers to all the mutations it receives, possibly from multiple clients, which provides the necessary serialization. It applies the mutation to its own local state in serial number order.
- 5.The primary forwards the write request to all secondary replicas. Each secondary replica applies mutations in the same serial number order assigned by the primary.
- 6.The secondaries all reply to the primary indicating that they have completed the operation.
- 7.The primary replies to the client. If there are any errors, client code will handle them.
2. Data Flow
To fully utilize each machine’s network bandwidth, the data is pushed linearly along a chain of chunkservers rather than distributed in some other topology (e.g., tree).
3. Atomic Record Appends
GFS provides an atomic append operation called record append. In a traditional write, the client specifies the offset at which data is to be written. Concurrent writes to the same region are not serializable: the region may end up containing data fragments from multiple clients. In a record append, however, the client specifies only the data. GFS appends it to the file at least once atomically (i.e., as one continuous sequence of bytes) at an offset of GFS’s choosing and returns that offset to the client.
4. Snapshot
The snapshot operation makes a copy of a file or a directory tree (the “source”) almost instantaneously, while minimizing any interruptions of ongoing mutations.
Reference: Google File System